Hollywood-style films may control viewers’ attention more than originally thought, according to a Kansas State University researcher.
Lester Loschky, associate professor of psychological sciences, recently published “What Would Jaws Do? The Tyranny of Film” in PLOS ONE. The study suggests viewers may have limited cognitive control of their eye movements while trying to understand films.
“Hollywood-style filmmakers have developed stimuli — such as shorter shot length, more motion in the frame and higher contrast — that is amazing at directing the viewers’ attention from moment to moment in exactly the way that the filmmaker wants,” Loschky said. “It is not that film producers have complete mind control because we willingly participate in it — we enjoy movies — but they do have a lot of control over our attention.”
Loschky compared eye movements of people who watched a three-minute clip of “Moonraker,” a 1979 James Bond film, with people who watched the last 12 seconds of the clip. His hypothesis, called the “Tyranny of Film,” was that film viewers’ eye movements are separate from a person’s understanding.
“We are investigating film perception and film comprehension together,” Loschky said. “In a static picture, people look at different things at different times, but during a movie suddenly everybody is looking at the same things at the same time.”
Loschky said that in the last 100 years, filmmakers slowly have gotten better at getting every viewer to look at the same place at the same time, a measurement called attentional synchrony. He attributes that to what he calls MTV-style editing, which is a greater frequency of cuts and shorter shot lengths. The researchers hypothesize that filmmakers are so good at influencing viewers’ eye movements in Hollywood-style movies that viewers’ understanding does not necessarily affect where they look.
“We wanted to know if a person’s understanding affects what they pay attention to while watching a movie,” Loschky said. “A lot of people in our area of psychology would assume that it does, but what we are finding out is not so much.”
To establish a difference in understanding, the researchers asked participants at the pinnacle moment at the end of the 12-second clip to predict what would happen next in the film. People in the context group, those who watched the longer segment, were more than twice as likely to immediately predict the next scene than people who watched the shorter segment, the no-context group.
“We call it the jumped-in-the-middle method,” Loschky said. “Imagine you’re watching a movie and your significant other comes in halfway through; they will not understand as quickly as you do because you know the context of the story. We are interested in that early time before they’ve caught up.”
After establishing a difference in understanding, Loschky compared eye movements of the two groups to see if the viewers’ attention was different or the same regardless of their understanding.
“Surprisingly, there are only very small, very subtle differences in the eye movements,” Loschky said. “When you look at the overall pattern, they look virtually identical, which suggests a high degree of attentional synchrony overall.”
Most of the subtle differences occurred in shot four, where the movie cuts from Bond’s nemesis, Jaws, falling after his parachute fails to open to a shot of a circus tent. The context group immediately predicted that Jaws would fall on the tent. The no context group was split into two subgroups: those who did predict Jaws would fall on the tent, called the no-context + inference group, and those who didn’t, called the no-context + no-inference group.
“A viewer’s mental model, or their understanding, doesn’t occur instantaneously; it occurs in stages and it is built up over time,” Loschky said. “When the viewers who jumped in the middle see a circus tent, their mental model may not have developed the reasoning that the circus tent is a solution to prevent the character, Jaws, from falling to his death.”
According to Loschky, while watching the circus tent shot, viewers in the context condition looked at the same places at the same time, while viewers in the no-context condition looked at more places. Loschky said these subtle differences in eye movements were because participants who didn’t have the full context of the clip were having a hard time understanding why they were being shown a circus tent.
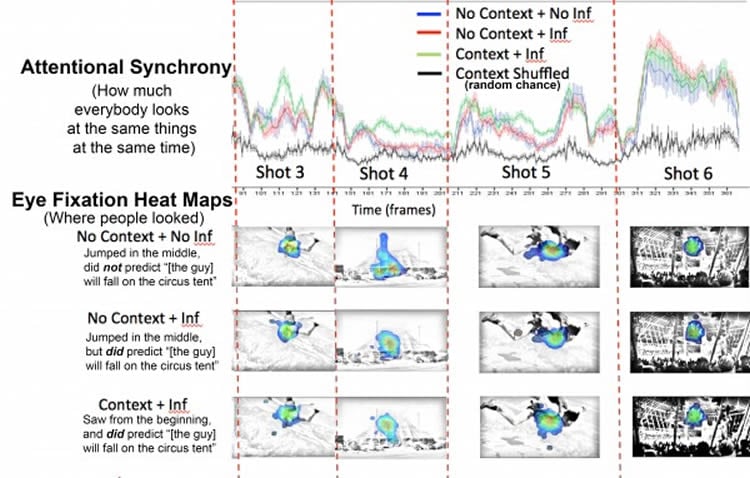
Both of the no context groups wanted to understand why they were seeing a circus tent but didn’t have the background to fully understand, so their eyes searched the image more. Those viewers in the no-context group who succeeded in making the inference looked longer in an effort to understand than those who didn’t make the inference, he said.
“It seems that your understanding of a movie is not clearly reflected in your eye movements at the broad level,” Loschky said. “However, if you do sophisticated eye movement analyses, you can find subtle differences in the eye movements. You have to really dig deep to find these differences and we think that is actually quite surprising.”
Funding: This research was funded by the Office of Naval Research; Abbott Nutrition through the Center for Nutrition, Learning, and Memory at the U. of I.; and the National Science Foundation.
Source: Les Loschky – Kansas State University
Image Source: The image is credited to Kansas State University.
Original Research: Full open access research for “What Would Jaws Do? The Tyranny of Film” by Lester C. Loschky, Adam M. Larson, Joseph P. Magliano, and Tim J. Smith in PLOS One. Published online November 25 2015 doi:10.1371/journal.pone.0142474
What Would Jaws Do? The Tyranny of Film
What is the relationship between film viewers’ eye movements and their film comprehension? Typical Hollywood movies induce strong attentional synchrony—most viewers look at the same things at the same time. Thus, we asked whether film viewers’ eye movements would differ based on their understanding—the mental model hypothesis—or whether any such differences would be overwhelmed by viewers’ attentional synchrony—the tyranny of film hypothesis. To investigate this question, we manipulated the presence/absence of prior film context and measured resulting differences in film comprehension and eye movements. Viewers watched a 12-second James Bond movie clip, ending just as a critical predictive inference should be drawn that Bond’s nemesis, “Jaws,” would fall from the sky onto a circus tent. The No-context condition saw only the 12-second clip, but the Context condition also saw the preceding 2.5 minutes of the movie before seeing the critical 12-second portion. Importantly, the Context condition viewers were more likely to draw the critical inference and were more likely to perceive coherence across the entire 6 shot sequence (as shown by event segmentation), indicating greater comprehension. Viewers’ eye movements showed strong attentional synchrony in both conditions as compared to a chance level baseline, but smaller differences between conditions. Specifically, the Context condition viewers showed slightly, but significantly, greater attentional synchrony and lower cognitive load (as shown by fixation probability) during the critical first circus tent shot. Thus, overall, the results were more consistent with the tyranny of film hypothesis than the mental model hypothesis. These results suggest the need for a theory that encompasses processes from the perception to the comprehension of film.
“What Would Jaws Do? The Tyranny of Film” by Lester C. Loschky, Adam M. Larson, Joseph P. Magliano, and Tim J. Smith in PLOS One. Published online November 25 2015 doi:10.1371/journal.pone.0142474