

Summary: Researchers have created a robot that can learn to visually predict how its partner will behave. This could help robots get along with other robots and humans more intuitively.
Source: Columbia University
Like a longtime couple who can predict each other’s every move, a Columbia Engineering robot has learned to predict its partner robot’s future actions and goals based on just a few initial video frames.
When two primates are cooped up together for a long time, we quickly learn to predict the near-term actions of our roommates, co-workers or family members. Our ability to anticipate the actions of others makes it easier for us to successfully live and work together. In contrast, even the most intelligent and advanced robots have remained notoriously inept at this sort of social communication. This may be about to change.
The study, conducted at Columbia Engineering’s Creative Machines Lab led by Mechanical Engineering Professor Hod Lipson, is part of a broader effort to endow robots with the ability to understand and anticipate the goals of other robots, purely from visual observations.
The researchers first built a robot and placed it in a playpen roughly 3×2 feet in size. They programmed the robot to seek and move towards any green circle it could see. But there was a catch: Sometimes the robot could see a green circle in its camera and move directly towards it. But other times, the green circle would be occluded by a tall red carboard box, in which case the robot would move towards a different green circle, or not at all.
After observing its partner puttering around for two hours, the observing robot began to anticipate its partner’s goal and path. The observing robot was eventually able to predict its partner’s goal and path 98 out of 100 times, across varying situations–without being told explicitly about the partner’s visibility handicap.
“Our initial results are very exciting,” says Boyuan Chen, lead author of the study, which was conducted in collaboration with Carl Vondrick, assistant professor of computer science, and published today by Nature Scientific Reports.
“Our findings begin to demonstrate how robots can see the world from another robot’s perspective. The ability of the observer to put itself in its partner’s shoes, so to speak, and understand, without being guided, whether its partner could or could not see the green circle from its vantage point, is perhaps a primitive form of empathy.”
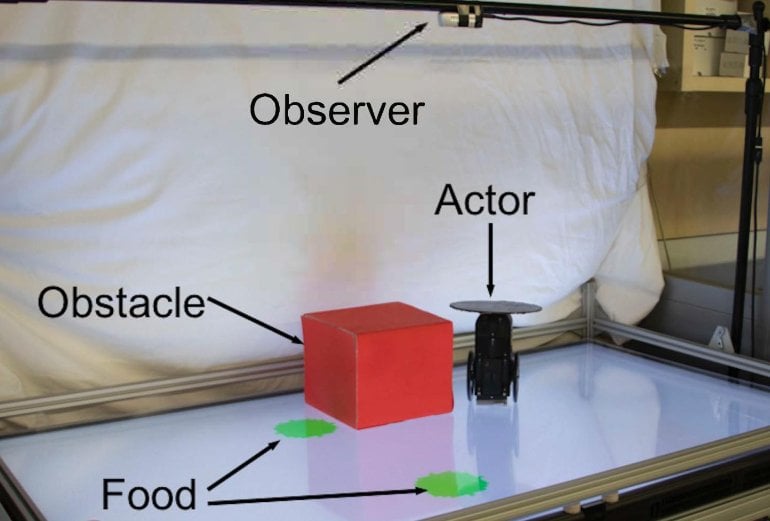
When they designed the experiment, the researchers expected that the Observer Robot would learn to make predictions about the Subject Robot’s near-term actions. What the researchers didn’t expect, however, was how accurately the Observer Robot could foresee its colleague’s future “moves” with only a few seconds of video as a cue.
The researchers acknowledge that the behaviors exhibited by the robot in this study are far simpler than the behaviors and goals of humans. They believe, however, that this may be the beginning of endowing robots with what cognitive scientists call “Theory of Mind” (ToM). At about age three, children begin to understand that others may have different goals, needs and perspectives than they do.
This can lead to playful activities such as hide and seek, as well as more sophisticated manipulations like lying. More broadly, ToM is recognized as a key distinguishing hallmark of human and primate cognition, and a factor that is essential for complex and adaptive social interactions such as cooperation, competition, empathy, and deception.
In addition, humans are still better than robots at describing their predictions using verbal language. The researchers had the observing robot make its predictions in the form of images, rather than words, in order to avoid becoming entangled in the thorny challenges of human language. Yet, Lipson speculates, the ability of a robot to predict the future actions visually is not unique: “We humans also think visually sometimes. We frequently imagine the future in our mind’s eyes, not in words.”
Lipson acknowledges that there are many ethical questions. The technology will make robots more resilient and useful, but when robots can anticipate how humans think, they may also learn to manipulate those thoughts.
“We recognize that robots aren’t going to remain passive instruction-following machines for long,” Lipson says. “Like other forms of advanced AI, we hope that policymakers can help keep this kind of technology in check, so that we can all benefit.”
About the Study
The study is titled “Visual Behavior Modelling for Robotic Theory of Mind”
Authors are: Boyuan Chen, Carl Vondrick and Hod Lipson, Mechanical Engineering and Computer Science, Columbia Engineering.
Funding: The study was supported by NSF NRI 1925157 and DARPA MTO grant L2M Program HR0011-18-2-0020.
The authors declare no financial or other conflicts of interest.
About this robotics research news
Source: Columbia University
Contact: Holly Evarts – Columbia University
Image: The image is credited to Creative Machines Lab/Columbia Engineering
Original Research: Open access.
“Visual behavior modelling for robotic theory of mind” by Boyuan Chen, Carl Vondrick & Hod Lipson. Scientific Reports
Abstract
Visual behavior modelling for robotic theory of mind
Behavior modeling is an essential cognitive ability that underlies many aspects of human and animal social behavior (Watson in Psychol Rev 20:158, 1913), and an ability we would like to endow robots. Most studies of machine behavior modelling, however, rely on symbolic or selected parametric sensory inputs and built-in knowledge relevant to a given task. Here, we propose that an observer can model the behavior of an actor through visual processing alone, without any prior symbolic information and assumptions about relevant inputs. To test this hypothesis, we designed a non-verbal non-symbolic robotic experiment in which an observer must visualize future plans of an actor robot, based only on an image depicting the initial scene of the actor robot. We found that an AI-observer is able to visualize the future plans of the actor with 98.5% success across four different activities, even when the activity is not known a-priori. We hypothesize that such visual behavior modeling is an essential cognitive ability that will allow machines to understand and coordinate with surrounding agents, while sidestepping the notorious symbol grounding problem. Through a false-belief test, we suggest that this approach may be a precursor to Theory of Mind, one of the distinguishing hallmarks of primate social cognition.




