Brain scans of Harry Potter readers yields computational model of reading.
Some people say that reading “Harry Potter and the Sorcerer’s Stone” taught them the importance of friends, or that easy decisions are seldom right. Carnegie Mellon University scientists used a chapter of that book to learn a different lesson: identifying what different regions of the brain are doing when people read.
Researchers from CMU’s Machine Learning Department performed functional magnetic resonance imaging (fMRI) scans of eight people as they read a chapter of that Potter book. They then analyzed the scans, cubic millimeter by cubic millimeter, for every four-word segment of that chapter. The result was the first integrated computational model of reading, identifying which parts of the brain are responsible for such subprocesses as parsing sentences, determining the meaning of words and understanding relationships between characters.
As Leila Wehbe, a Ph.D. student in the Machine Learning Department, and Tom Mitchell, the department head, report today in the online journal PLOS ONE, the model was able to predict fMRI activity for novel text passages with sufficient accuracy to tell which of two different passages a person was reading with 74 percent accuracy.
“At first, we were skeptical of whether this would work at all,” Mitchell said, noting that analyzing multiple subprocesses of the brain at the same time is unprecedented in cognitive neuroscience. “But it turned out amazingly well and now we have these wonderful brain maps that describe where in the brain you’re thinking about a wide variety of things.”
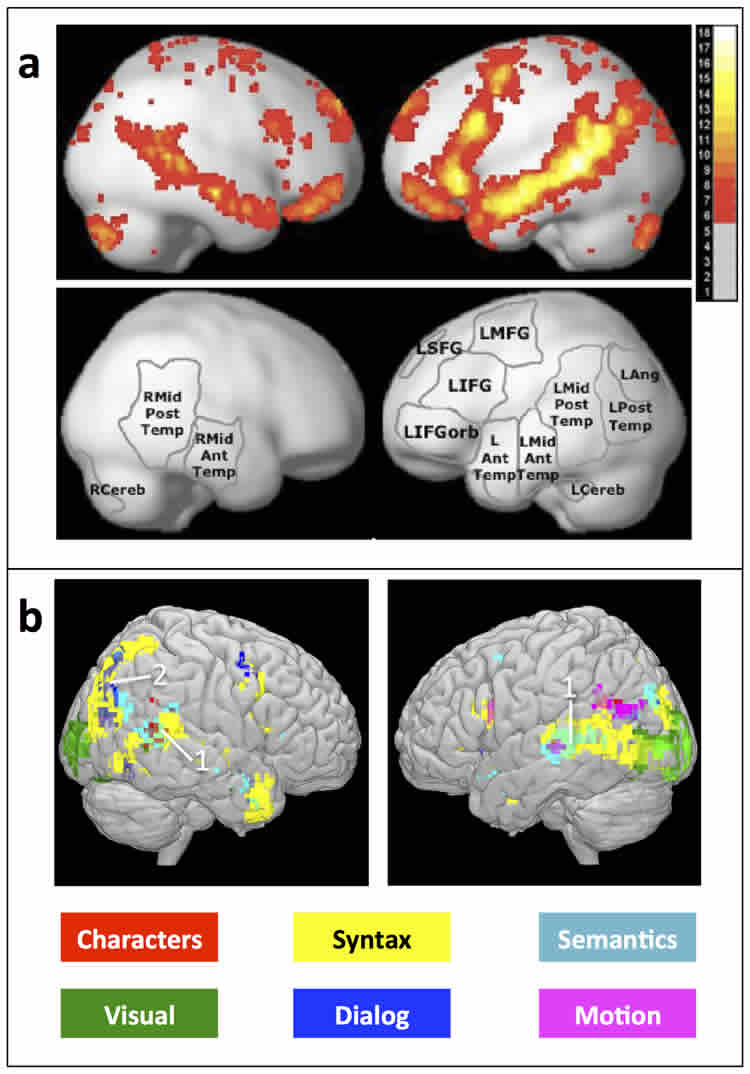
“If I’m having trouble learning a new language, I may have a hard time figuring out exactly what I don’t get,” Mitchell said. “When I can’t understand a sentence, I can’t articulate what it is I don’t understand. But a brain scan might show that the region of my brain responsible for grammar isn’t activating properly, or perhaps instead I’m not understanding the individual words.”
Researchers at Carnegie Mellon and elsewhere have used fMRI scans to identify activation patterns associated with particular words or phrases or even emotions. But these have always been tightly controlled experiments, with only one variable analyzed at a time. The experiments were unnatural, usually involving only single words or phrases, but the slow pace of fMRI — one scan every two seconds — made other approaches seem unfeasible.
Wehbe nevertheless was convinced that multiple cognitive subprocesses could be studied simultaneously while people read a compelling story in a near-normal manner. She believed that using a real text passage as an experimental stimulus would provide a rich sample of the different word properties, which could help to reveal which brain regions are associated with these different properties.
“No one falls asleep in the scanner during Leila’s experiments,” Mitchell said.
They devised a technique in which people see one word of a passage every half second — or four words for every two-second fMRI scan. For each word, they identified 195 detailed features — everything from the number of letters in the word to its part of speech. They then used a machine learning algorithm to analyze the activation of each cubic centimeter of the brain for each four-word segment.
Bit by bit, the algorithm was able to associate certain features with certain regions of the brain, Wehbe said.
“The test subjects read Chapter 9 of Sorcerer’s Stone, which is about Harry’s first flying lesson,” she noted. “It turns out that movement of the characters — such as when they are flying their brooms – is associated with activation in the same brain region that we use to perceive other people’s motion. Similarly, the characters in the story are associated with activation in the same brain region we use to process other people’s intentions.”
Exactly how the brain creates these neural encodings is still a mystery, they said, but it is the beginning of understanding what the brain is doing when a person reads.
“It’s sort of like a DNA fingerprint — you may not understand all aspects of DNA’s function, but it guides you in understanding cell function or development,” Mitchell said. “This model of reading initially is that kind of a fingerprint.”
A complementary study by Wehbe and Mitchell, presented earlier this fall at the Conference on Empirical Methods in Natural Language Processing, used magnetoencephalography (MEG) to record brain activity in subjects reading Harry Potter. MEG can record activity every millisecond, rather than every two seconds as in fMRI scanning, but can’t localize activity with the precision of fMRI. Those findings suggest how words are integrated into memory — how the brain first visually perceives a word and then begins accessing the properties of the word, and fitting it into the story context.
This research was supported by the National Science Foundation, the National Institute of Child Health and Human Development and the Rothberg Brain Imaging Award.
Contact: Byron Spice – Carnegie Mellon
Source: Carnegie Mellon press release
Image Source: The image is credited to Mitchell et al./PLOS ONE and is adapted from the open access research paper
Original Research: Full open access research for “Simultaneously Uncovering the Patterns of Brain Regions Involved in Different Story Reading Subprocesses” by Leila Wehbe, Brian Murphy, Partha Talukdar, Alona Fyshe, Aaditya Ramdas, and Tom Mitchell in PLOS ONE. Published online November 26 2014 doi:10.1371/journal.pone.0112575
Simultaneously Uncovering the Patterns of Brain Regions Involved in Different Story Reading Subprocesses
Story understanding involves many perceptual and cognitive subprocesses, from perceiving individual words, to parsing sentences, to understanding the relationships among the story characters. We present an integrated computational model of reading that incorporates these and additional subprocesses, simultaneously discovering their fMRI signatures. Our model predicts the fMRI activity associated with reading arbitrary text passages, well enough to distinguish which of two story segments is being read with 74% accuracy. This approach is the first to simultaneously track diverse reading subprocesses during complex story processing and predict the detailed neural representation of diverse story features, ranging from visual word properties to the mention of different story characters and different actions they perform. We construct brain representation maps that replicate many results from a wide range of classical studies that focus each on one aspect of language processing and offer new insights on which type of information is processed by different areas involved in language processing. Additionally, this approach is promising for studying individual differences: it can be used to create single subject maps that may potentially be used to measure reading comprehension and diagnose reading disorders.
“Simultaneously Uncovering the Patterns of Brain Regions Involved in Different Story Reading Subprocesses” by Leila Wehbe, Brian Murphy, Partha Talukdar, Alona Fyshe, Aaditya Ramdas, and Tom Mitchell in PLOS ONE. oi:10.1371/journal.pone.0112575.