

Summary: A new artificial neural network can assess a viewer’s reaction to movies based on patterns of facial expressions. With enough information, researchers say the ANN will be able to assess how an audience is reacting to a movie and predict an individual’s response based on a few minutes of observation.
Source: CalTech.
Software automatically discovers patterns in facial expressions.
Engineers have created a new deep-learning software capable of assessing complex audience reactions to movies using the viewer’s facial expressions. Developed by Disney Research in collaboration with Yisong Yue of Caltech and colleagues at Simon Fraser University, the software relies on a new algorithm known as factorized variational autoencoders (FVAEs).
Variational autoencoders use deep learning to automatically translate images of complex objects, like faces, into sets of numerical data, also known as a latent representation or encoding. The contribution of Yue and his colleagues was to train the autoencoders to incorporate metadata (pertinent information about the data being analyzed). In the parlance of the field, they used the metadata to define an encoding space that can be factorized.
In this case, the factorized variational autoencoder takes images of the faces of people watching movies and breaks them down into a series of numbers representing specific features: one number for how much a face is smiling, another for how wide open the eyes are, etc. Metadata then allow the algorithm to connect those numbers with other relevant bits of data—for example, with other images of the same face taken at different points in time, or of other faces at the same point in time.
With enough information, the system can assess how an audience is reacting to a movie so accurately that it can predict an individual’s responses based on just a few minutes of observation, says Disney research scientist Peter Carr. The technique’s potential goes far beyond the theater, says Yue, assistant professor of computing and mathematical sciences in Caltech’s Division of Engineering and Applied Science.
“Understanding human behavior is fundamental to developing AI [artificial intelligence] systems that exhibit greater behavioral and social intelligence. For example, developing AI systems to assist in monitoring and caring for the elderly relies on being able to pick up cues from their body language. After all, people don’t always explicitly say that they are unhappy or have some problem,” Yue says.
The team will present its findings at the IEEE Conference on Computer Vision and Pattern Recognition July 22 in Honolulu.
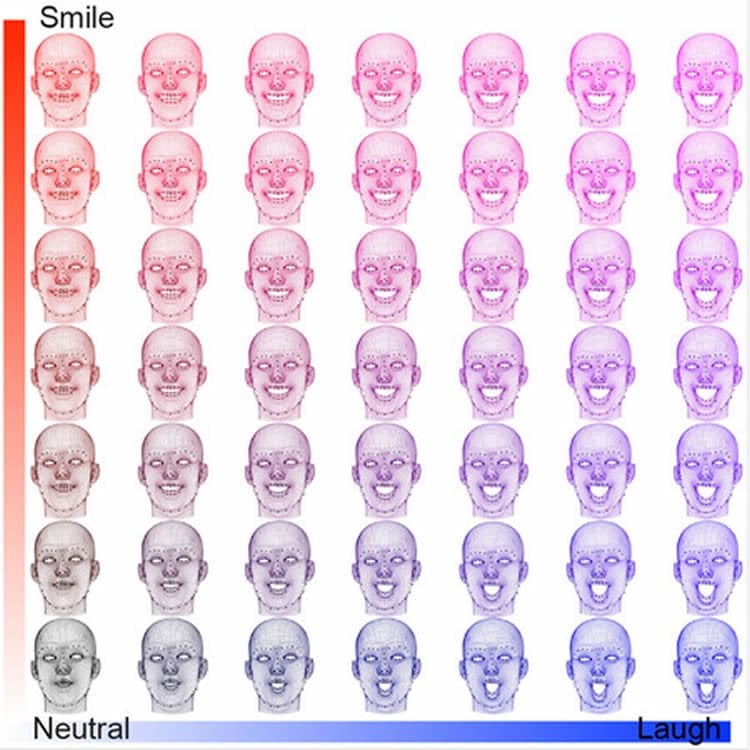
“We are all awash in data, so it is critical to find techniques that discover patterns automatically,” says Markus Gross, vice president for research at Disney Research. “Our research shows that deep-learning techniques, which use neural networks and have revolutionized the field of artificial intelligence, are effective at reducing data while capturing its hidden patterns.”
The research team applied FVAEs to 150 showings of nine movies, including Big Hero 6, The Jungle Book, and Star Wars: The Force Awakens. They used a 400-seat theater instrumented with four infrared cameras to monitor the faces of the audience in the dark. The result was a data set that included 68 landmarks per face captured from a total of 3,179 audience members at a rate of two frames per second—yielding some 16 million individual images of faces.
“It’s more data than a human is going to look through,” Carr says. “That’s where computers come in—to summarize the data without losing important details.”
The pattern recognition technique is not limited to faces. It can be used on any time-series data collected from a group of objects. “Once a model is learned, we can generate artificial data that looks realistic,” Yue says. For instance, if FVAEs were used to analyze a forest—noting differences in how trees respond to wind based on their type and size as well as wind speed—those models could be used to create an animated simulation of the forest.
In addition to Carr, Deng, Mandt, and Yue, the research team included Rajitha Navarathna and Iain Matthews of Disney Research and Greg Mori of Simon Fraser University. The study, titled “Factorized Variational Autoencoders for Modeling Audience Reactions to Movies,” was funded by Disney Research.
Source: Robert Perkins – CalTech
Image Source: NeuroscienceNews.com image is credited to Yisong Yue Laboratory/Caltech.
Original Research: Full open access research for “Factorized Variational Autoencoders for Modeling Audience Reactions to Movies” by Deng, Zhiwei and Navarathna, Rajitha and Carr, Peter and Mandt, Stephan and Yue, Yisong and Matthews, Iain and Mori, Greg is available from CalTech.
The researchers presented their findings at IEEE Conference on Computer Vision and Pattern Recognition July 22 in Honolulu.
[cbtabs][cbtab title=”MLA”]CalTech “Neural Networks Model Audience Reactions to Movies.” NeuroscienceNews. NeuroscienceNews, 2 August 2017.
<neural-network-audience-reaction-7222/>.[/cbtab][cbtab title=”APA”]CalTech (2017, August 2). Neural Networks Model Audience Reactions to Movies. NeuroscienceNew. Retrieved August 2, 2017 from neural-network-audience-reaction-7222/[/cbtab][cbtab title=”Chicago”]CalTech “Neural Networks Model Audience Reactions to Movies.” neural-network-audience-reaction-7222/ (accessed August 2, 2017).[/cbtab][/cbtabs]
Abstract
Factorized Variational Autoencoders for Modeling Audience Reactions to Movies
Matrix and tensor factorization methods are often used
for finding underlying low-dimensional patterns from noisy
data. In this paper, we study non-linear tensor factorization methods based on deep variational autoencoders. Our approach is well-suited for settings where the relationship between the latent representation to be learned and the raw data representation is highly complex. We apply our approach to a large dataset of facial expressions of movie-watching audiences (over 16 million faces). Our experiments show that compared to conventional linear factorization methods, our method achieves better reconstruction of the data, and further discovers interpretable latent factors.
“Injury-induced gp230 cytokine signaling in peripheral ganglia is reduced in diabetes mellitus” by Jon P. Niemi, Angela R. Filous, Alicia DeFrancesco, Jane A. Lindborg, Nisha A. Malhotra, Gina N. Wilson, Bowen Zhou, Samuel D. Crish, and Richard E. Zigmond in Experimental Neurology. Published online June 20 2017 doi:20.2026/j.expneurol.2017.06.020




