

Summary: A new voice manipulation algorithm allows researchers to visualize the neural codes people use to judge others by the tone of their voices.
Source: CNRS.
You can hear the perfect hello. And now you can see it too. Researchers from the CNRS, the ENS, and Aix-Marseille University have established an experimental method that unveils the filter—that is, mental representation—we use to judge people when hearing them say a word as simple as “hello”. What is the ideal intonation for coming across as determined or trustworthy? This method is already used by these researchers for clinical purposes, with stroke survivors, and it opens many new doors for the study of language perception. The team’s findings are published in PNAS.
When people you meet for the first time say hello, do they strike you as friendly or hostile? The linguistic and social judgments we make when hearing speech are based on intonation. Just as we have a mental image of what an apple looks like—round, green or red, with a stem, etc.—we form mental representations of others’ personalities according to the acoustic qualities of their voices. For the first time ever, researchers have managed to visually model these mental representations and compare those of different individuals.
To do this, they developed a computer program for voice manipulation called CLEESE. This software can take the recording of a single word and randomly generate thousands of other variant pronunciations that are all realistic but each unique in their melody—sort of like putting makeup on the original recording. Then, by analyzing participants’ responses when hearing these different pronunciations, the researchers were able to experimentally determine what intonation makes a hello seem sincere. To sound determined, a French speaker must pronounce bonjour (French for “hello”) with a descending pitch, putting emphasis on the second syllable sound-determined-woman/sound-determined-man . On the other hand, to inspire trust, the pitch must rise quickly at the end of the word sound-trustworthy-woman/sound-trustworthy-man. Using this software, the team is thus able to visualize the “code” people use to judge others by their voices, and has shown that the same code applies no matter the sex of the listener or the speaker.
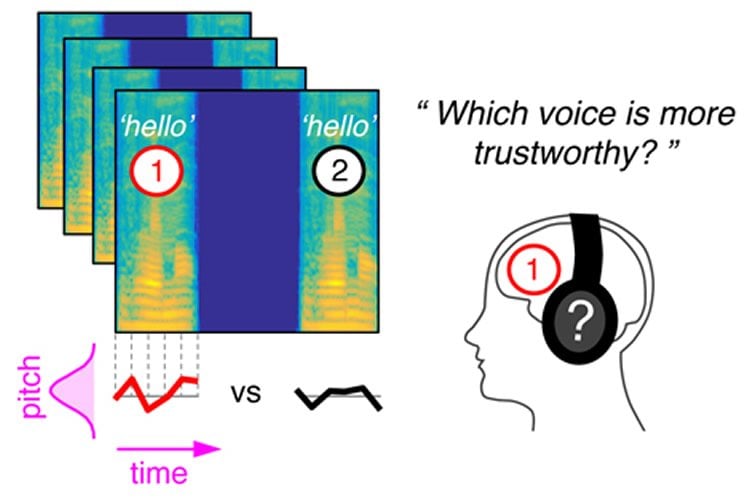
This method of investigation could be used to answer many other questions in the field of language perception. For example, how do these findings play out at sentence level? And do mental representations vary with the language being spoken? It may also serve to understand how emotions are represented by autistic individuals.
The team members themselves have already found a clinical application for the program: to study how words are interpreted by survivors of a stroke, an event which can alter how they perceive vocal intonation. Whether for the purposes of medical monitoring or diagnosis, the researchers would like to use their method to detect anomalies in language perception and possibly make it a tool for patient rehabilitation.
Source: CNRS
Publisher: Organized by NeuroscienceNews.com.
Image Source: NeuroscienceNews.com image is credited to CNRS/ENS/AMU.
Original Research: Open access research for “Cracking the social code of speech prosody using reverse correlation” by Emmanuel Ponsot, Juan José Burred, Pascal Belin and Jean-Julien Aucouturier in PNAS. Published March 26 2018.
doi:10.1073/pnas.1716090115
[cbtabs][cbtab title=”MLA”]CNRS “How to Make a Good Impression When Saying “Hello”.” NeuroscienceNews. NeuroscienceNews, 31 March 2018.
<https://neurosciencenews.com/introduction-impression-8716/>.[/cbtab][cbtab title=”APA”]CNRS (2018, March 31). How to Make a Good Impression When Saying “Hello”. NeuroscienceNews. Retrieved March 31, 2018 from https://neurosciencenews.com/introduction-impression-8716/[/cbtab][cbtab title=”Chicago”]CNRS “How to Make a Good Impression When Saying “Hello”.” https://neurosciencenews.com/introduction-impression-8716/ (accessed March 31, 2018).[/cbtab][/cbtabs]
Abstract
Cracking the social code of speech prosody using reverse correlation
Human listeners excel at forming high-level social representations about each other, even from the briefest of utterances. In particular, pitch is widely recognized as the auditory dimension that conveys most of the information about a speaker’s traits, emotional states, and attitudes. While past research has primarily looked at the influence of mean pitch, almost nothing is known about how intonation patterns, i.e., finely tuned pitch trajectories around the mean, may determine social judgments in speech. Here, we introduce an experimental paradigm that combines state-of-the-art voice transformation algorithms with psychophysical reverse correlation and show that two of the most important dimensions of social judgments, a speaker’s perceived dominance and trustworthiness, are driven by robust and distinguishing pitch trajectories in short utterances like the word “Hello,” which remained remarkably stable whether male or female listeners judged male or female speakers. These findings reveal a unique communicative adaptation that enables listeners to infer social traits regardless of speakers’ physical characteristics, such as sex and mean pitch. By characterizing how any given individual’s mental representations may differ from this generic code, the method introduced here opens avenues to explore dysprosody and social-cognitive deficits in disorders like autism spectrum and schizophrenia. In addition, once derived experimentally, these prototypes can be applied to novel utterances, thus providing a principled way to modulate personality impressions in arbitrary speech signals.




