Summary: Researchers reveal how a repeating nucleotide sequence in the gene for a mutant protein may trigger Huntington’s disease.
Source: Rice University.
Rice University scientists analyze repeats in proteins implicated in neurological diseases.
Rice University scientists have uncovered new details about how a repeating nucleotide sequence in the gene for a mutant protein may trigger Huntington’s and other neurological diseases.
Researchers at Rice’s Center for Theoretical Biological Physics used computer models to analyze proteins suspected of misfolding and forming plaques in the brains of patients with neurological diseases. Their simulations confirmed experimental results by other labs that showed the length of repeating polyglutamine sequences contained in proteins is critical to the onset of disease.
The study led by Rice bioscientist Peter Wolynes appears in the Journal of the American Chemical Society.
Glutamine is the amino acid coded for by the genomic trinucleotide CAG. Repeating glutamines, called polyglutamines, are normal in huntingtin proteins, but when the DNA is copied incorrectly, the repeating sequence of glutamines can become too long. The result can be diseases like Huntington’s or spinocerebellar ataxia.
The number of repeats of glutamine can grow as the genetic code information is passed down through generations. That means a healthy parent whose huntingtin gene encodes proteins with 35 repeats may produce a child with 36 repeats. A person having the longer repeat is likely to develop Huntington’s disease.
Aggregation in Huntington’s typically begins only when polyglutamine chains reach a critical length of 36 repeats. Studies have demonstrated that longer repeat chains can make the disease more severe and its onset earlier.
The paper builds upon techniques used in an earlier study of amyloid beta proteins. That study was the lab’s first attempt to model the energy landscape of amyloid aggregation, which has been implicated in Alzheimer’s disease.
This time, Wolynes and his team were interested in knowing how the varying length of repeats — as few as 20 and as many as 50 — influenced how aggregates form.
“The final form of the protein detected in people who have Huntington’s disease is a macroscopic aggregate made of many molecules, much like an ice crystal formed out of water has many molecules in it,” Wolynes said. “This process needs to start somewhere, and that would be with a nucleus, the smallest-size cluster that will then be able to finish the process and grow to macroscopic size.
“People knew that the length of the repeats is correlated with the severity of a disease, but we wanted to know why that matters to the critical nucleus size,” he said.
Experiments had demonstrated that sequences of 20 repeats or less remained unfolded – or “noodle-y,” as Wolynes described them; they were able to clump into a nucleus only when four or more were gathered together in proximity.
The researchers’ simulations showed how sequences with 30 repeats or more are able to fold by themselves without partners into hairpin shapes, which are the building blocks for troublesome aggregates. Thus, for the longer sequences, even a single protein can begin the aggregation process, especially at high concentrations.
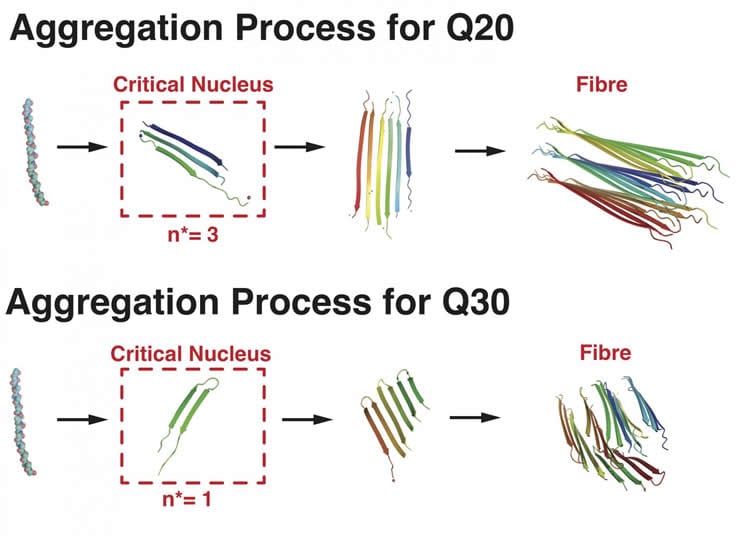
The Rice team found that at intermediate lengths between 20 and 30 repeats, polyglutamine sequences can choose between straight or hairpin configurations. While longer and shorter sequences form aligned fiber bundles, simulations showed intermediate sequences are more likely to form disordered, branched structures.
“We don’t know if branching is good or bad,” Wolynes said. “But it explains the weird shapes the experimentalists get in the test tube.”
Mutations that would encourage polyglutamine sequences to remain unfolded would raise the energy barrier to aggregation, they found. “What’s ironic is that while Huntington’s has been classified as a misfolding disease, it seems to happen because the protein, in the bad case of longer repeats, carries out an extra folding process that it wasn’t supposed to be doing,” Wolynes said.
The team’s ongoing study is now looking at how the complete huntingtin protein, which contains parts in addition to the polyglutamine repeats, aggregates.
Rice graduate student Mingchen Chen is lead author of the paper. Co-authors are Rice postdoctoral researcher Min-Yeh Tsai and research scientist Weihua Zheng. Wolynes is the D.R. Bullard-Welch Foundation Professor of Science, a professor of chemistry, of biochemistry and cell biology, of physics and astronomy and of materials science and nanoengineering at Rice and a senior investigator of the NSF-funded Center for Theoretical Biological Physics at Rice.
Funding: The National Institute of General Medical Sciences and the Ministry of Science and Technology, Taiwan, supported the research. The researchers used the NSF-supported DAVinCI supercomputer administered by Rice’s Ken Kennedy Institute for Information Technology.
Source: Mike Williams – Rice University
Image Source: NeuroscienceNews.com image is credited to Mingchen Chen/Rice University.
Original Research: Abstract for “The Aggregation Free Energy Landscapes of Polyglutamine Repeats” by Mingchen Chen, MinYeh Tsai, Weihua Zheng, and Peter G. Wolynes in JACS. Published online October 26 2016 doi:10.1021/jacs.6b08665
[cbtabs][cbtab title=”MLA”]Rice University. “Hunt for Huntington’s Cause Yields Clues.” NeuroscienceNews. NeuroscienceNews, 10 November 2016.
<https://neurosciencenews.com/huntingtons-proteins-computer-model-5478/>.[/cbtab][cbtab title=”APA”]Rice University. (2016, November 10). Hunt for Huntington’s Cause Yields Clues. NeuroscienceNews. Retrieved November 10, 2016 from https://neurosciencenews.com/huntingtons-proteins-computer-model-5478/[/cbtab][cbtab title=”Chicago”]Rice University. “Hunt for Huntington’s Cause Yields Clues.” https://neurosciencenews.com/huntingtons-proteins-computer-model-5478/ (accessed November 10, 2016).[/cbtab][/cbtabs]
Abstract
The Aggregation Free Energy Landscapes of Polyglutamine Repeats
Aggregates of proteins containing polyglutamine (polyQ) repeats are strongly associated with several neurodegenerative diseases. The length of the repeats correlates with the severity of the disease. Previous studies have shown that pure polyQ peptides aggregate by nucleated growth polymerization and that the size of the critical nucleus (n*) decreases from tetrameric to dimeric and monomeric as length increases from Q18 to Q26. Why the critical nucleus size changes with repeat-length has been unclear. Using the associative memory, water-mediated, structure and energy model, we construct the aggregation free energy landscapes for polyQ peptides of different repeat-lengths. These studies show that the monomer of the shorter repeat-length (Q20) prefers an extended conformation and that its aggregation indeed has a trimeric nucleus (n* ∼ 3), while a longer repeat-length monomer (Q30) prefers a β-hairpin conformation which then aggregates in a downhill fashion at 0.1 mM. For an intermediate length peptide (Q26), there is an equal preference for hairpin and extended forms in the monomer which leads to a mixed inhomogeneous nucleation mechanism for fibrils. The predicted changes of monomeric structure and nucleation mechanism are confirmed by studying the aggregation free energy profile for a polyglutamine repeat with site-specific PG mutations that favor the hairpin form, giving results in harmony with experiments on this system.
“The Aggregation Free Energy Landscapes of Polyglutamine Repeats” by Mingchen Chen, MinYeh Tsai, Weihua Zheng, and Peter G. Wolynes in JACS. Published online October 26 2016 doi:10.1021/jacs.6b08665